How Agent Memory Works
Every AI agent you've ever used has the same problem. It forgets you.
Every API call to a large language model starts from zero. The three-hour conversation you had yesterday? Gone. The preferences you explained, the decisions you made, the context you carefully built up? None of it carries over. Unless something external bridges that gap, your agent wakes up every session with amnesia.
This is the memory problem. And it's one of the defining constraints of working with AI right now. Context windows keep getting bigger (128K+ tokens on frontier models), but they're still finite, still expensive, and still too small for any agent that needs to maintain a long-term relationship with you.
I spent months thinking about this problem before I built Engram. This article is everything I learned along the way: the different types of memory, the approaches people are using, the tradeoffs, and where I think this is all heading.
The three types of memory
Cognitive science gives us a useful framework that maps surprisingly well to AI systems.

Episodic memory is "what happened." Conversations, events, interactions. The raw record of experience. When you tell your agent you prefer TypeScript over Python, that conversation is an episode.
Semantic memory is "what I know." Facts, preferences, relationships. Knowledge extracted from experience but stripped of the timestamp. "Thomas prefers TypeScript" is a semantic memory. It came from an episode, but it stands on its own.
Procedural memory is "how to do things." Skills, workflows, learned patterns. This is the hardest to implement in agents. Most systems today handle it through tool definitions and system prompts rather than learned behavior.
Most of the action right now is in episodic and semantic memory. The real question is how to store, organize, and retrieve them efficiently. You want to remember everything (completeness) while retrieving only what's relevant (precision), and you want to do it without blowing your token budget (efficiency). Those three things are in constant tension.
The approaches
There are seven distinct strategies being used in production today. They sit on a spectrum from dead-simple to architecturally complex, and each one makes a different bet about where to invest intelligence.
1. Full context injection
The simplest approach: dump the entire conversation history into every prompt. No retrieval logic, no indexing, no extraction. Just raw context.

It works surprisingly well for short conversations. Accuracy is near-perfect because the model sees everything. But token costs scale linearly. A 128K-token context at GPT-4 pricing runs about $1.28 per query on input alone. An agent handling 1,000 queries a day would burn $1,280 daily just on memory. And eventually you hit the context window limit and can't fit everything in anyway.
This is the approach most people start with. It's also the one that breaks first.
2. Manual memory files
The agent (or you) maintains a markdown file of important facts. Think of it as a scratchpad the agent reads at the start of each session. Cursor, Windsurf, and tools like OpenClaw use variants of this pattern. I used it myself for months with Obsidian vaults before I built something better.

It's token-efficient and easy to debug. You can open the file and see exactly what the agent knows. But it doesn't scale. Someone has to decide what matters before knowing what will be asked. A passing mention of a restaurant might turn out to be critical three months later, and the manual approach will have skipped it.
3. Vector search (RAG)
The industry standard first step: embed memories as vectors, retrieve by cosine similarity. This is what most tutorials teach and most prototypes use.

It's fast, cheap, and well-understood. There's a great ecosystem around it (Pinecone, Weaviate, ChromaDB). But cosine similarity is a blunt instrument. It finds memories that sound like the query, not memories that are relevant to the query. "Where does Sarah work?" and "Sarah mentioned she was tired" might score similarly because both mention Sarah. That's a fundamental limitation.
4. Mem0
Mem0 is the most popular dedicated memory library, YC-backed with 50K+ in the community. Their approach: extract structured facts from conversations at write time, then retrieve them with vector search. So "Sarah mentioned she started a new job at Google last week" becomes the memory "Sarah works at Google."
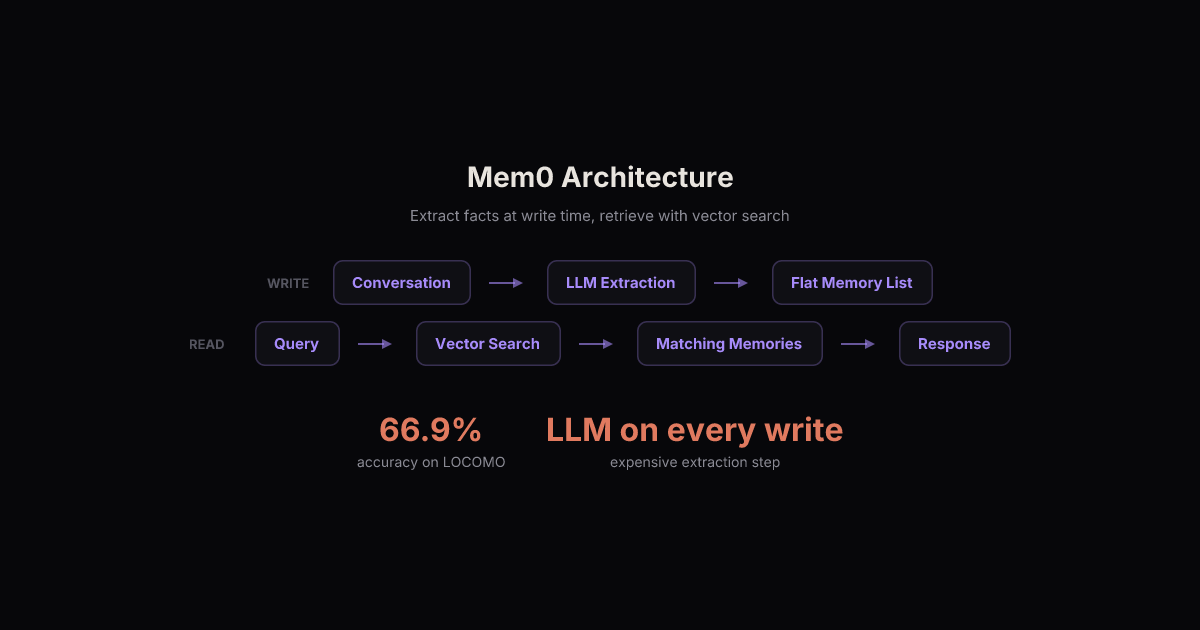
The extraction step is smart. But it has a fundamental problem: you have to decide what matters before you know what questions will be asked. The extractor runs at write time, when you have the least information about what will be relevant later.
5. Letta (formerly MemGPT)
Letta takes a different angle: the agent itself manages its own memory. Inspired by operating system virtual memory, it gives the agent explicit tools to read, write, and search across three memory tiers: core memory (always in context), archival memory (search-based), and recall memory (recent messages).

It's an elegant abstraction. But it depends on the agent reliably choosing to store, update, and delete memories. That's a lot of prompt engineering burden, and self-editing can be brittle.
6. Zep
Zep attacks the problem I mentioned earlier that most systems struggle with: time. It's built around Graphiti, an open-source temporal knowledge graph engine that tracks how facts change.

The architecture has three layers. An episode subgraph stores raw conversations. A semantic entity subgraph extracts people, places, and relationships from those episodes. And a community subgraph clusters related entities into higher-level summaries. When new information contradicts an existing fact, Zep invalidates the old edge and preserves the history. "Sarah works at Google" doesn't get deleted when she moves to Anthropic. It gets marked as expired, and the new fact takes over.
This is the most sophisticated approach to the temporal problem I've seen. On the LongMemEval benchmark, Zep improved accuracy by 18.5% over baseline while cutting latency by 90%. It's strong where most systems are weak.
The tradeoff is infrastructure. Zep runs on Neo4j and requires LLM calls on every write for entity extraction and resolution. It's enterprise-grade tooling with enterprise-grade complexity.
7. Engram
This is where I ended up. Engram inverts the dominant pattern. Instead of investing intelligence at write time, it invests intelligence at read time.

The write path is lightweight. When a memory comes in, Engram auto-extracts entities and topics, generates an embedding, and adds it to the knowledge graph. No LLM call needed.
The read path is where the intelligence lives. When a query arrives, the system knows exactly what it needs to find. It runs spreading activation through the knowledge graph (like neurons firing in your brain, where activating one node partially activates connected nodes), boosts memories that share entities with the query, applies stability scoring (similar to spaced repetition), and combines all of that with vector similarity for a final ranked result.
The key insight: vector search alone scores 64.5% on the LOCOMO benchmark. Adding Engram's intelligence layer on top of the same vectors pushes it to 79.6%. That's a 15-point improvement from smarter retrieval, not more data.
The benchmarks
I ran Engram against LOCOMO, the standard benchmark for agent memory. 1,189 questions across 10 long conversations.
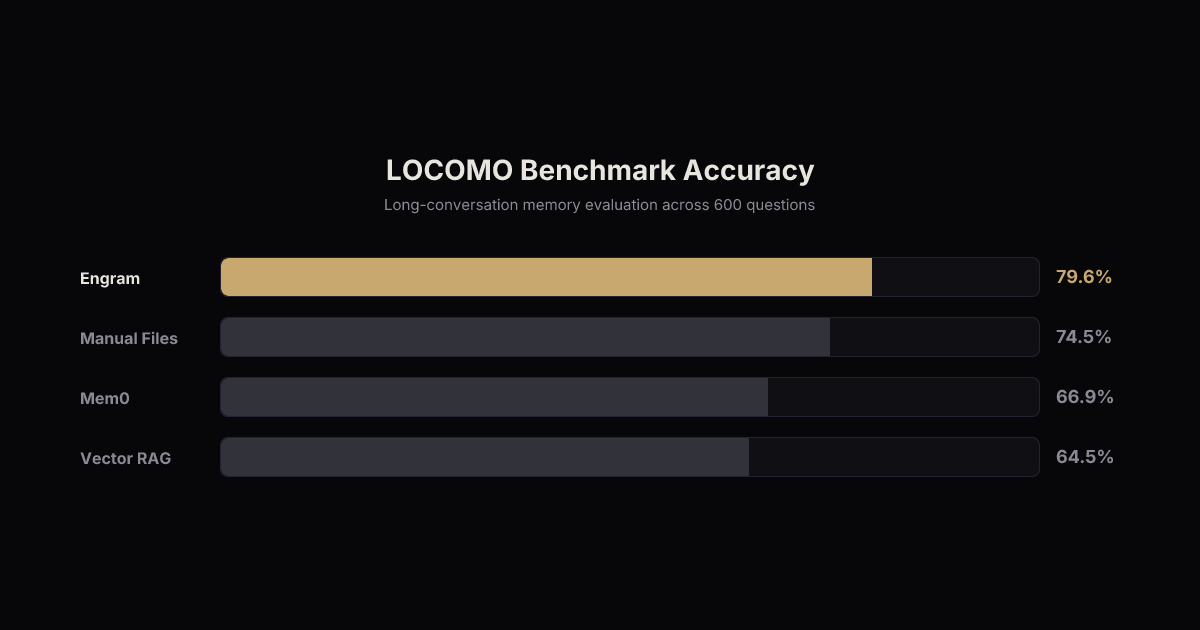
Engram scored 79.6% recall accuracy, compared to Mem0's 66.9% and OpenAI Memory's 53.1%. On the Letta core-memory-read benchmark (1,100 questions), Engram hit 97.0%, essentially matching full context injection (96.9%) while using 30x fewer tokens.
The token efficiency matters more than people realize. Engram uses 776 tokens per query. Full context injection uses 22,976. That's the difference between a viable production system and one that bankrupts you.
The next frontier: temporal reasoning
The hardest unsolved problem in agent memory is time.

Sarah worked at Google in January. She switched to Anthropic in March. When you ask "where does Sarah work?" today, both memories score high on relevance. Full context injection handles this naturally because the model sees messages in chronological order and picks the latest one. But any system that retrieves by relevance rather than recency has to solve this explicitly.
This is where the field is heading next. The strategies that are emerging include contradiction detection, where an NLI model flags when new memories conflict with existing ones. Recency boost, where newer memories get a time-decay bonus in the scoring function. And temporal spreading activation, where the knowledge graph itself encodes time relationships so the graph traversal can prefer more recent edges. Engram is actively building all three.
Where this is heading
The agent memory space is moving fast. Every approach on this list makes a different bet about where to invest intelligence, and the right answer depends on your use case. Full context is fine for short conversations. Manual files work for small projects with a human in the loop. Vector RAG is the quick prototype.
I built Engram because I wanted something that was accurate, efficient, and honest about its tradeoffs. If you're working with AI agents and the memory problem resonates with you, the full research is on the site, and the source is on GitHub.